I'm a firm believer that every technology professional has stumbling blocks, something that no matter how hard they try, it's just difficult to "make that knowledge stick".
For some, it's RegEx, for others it could be DNS configuration.
One of mine is around networking, subnets, and netmasks.
Unfortunately, understanding these concepts is essential to AWS Virtual Private Cloud (VPC) configuration.
Here's how I set up my VPC, Subnets, and, Route Tables, and Internet Gateways for my EC2 / ECS studies.
VPC: This is the starting point.
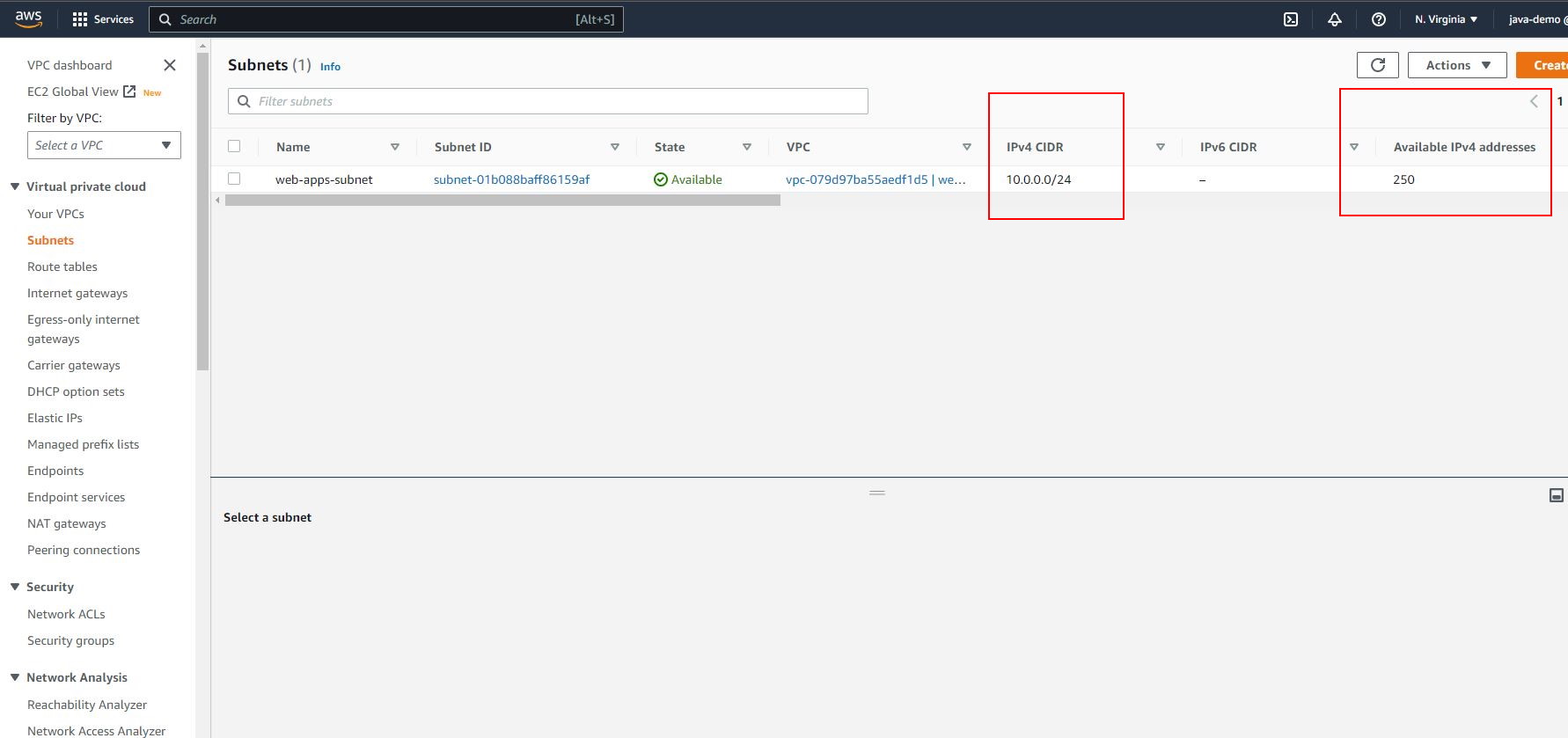
I created a new VPC with the name web-apps and an IPv4 CIDR block of: 10.0.0.0/24
/24 is the equivalent of a Netmask of 255.255.255.0
The way I've learned to think of CIDR blocks and Netmasks for IPv4 ... there are 4 Octets, and each Octet is 8 bits.
/24 means that there are 24 1-bits in the Netmask, taking up 3 of the Octets, hence 255.255.255.0.
The higher the number (up to 32, or all 4 Octets, the more restrictive).
The lower the number (down to 0, or none of the Octets, the less restrictive).
So 0.0.0.0/0 on something like an Ingress Rule means "let the world in".
Going back to my VPC, CIDR block of: 10.0.0.0/24
32 (all bits in an IPv4 Address) - 24 (from CIDR Block) = 8 (number of bits available for addresses in my VPC).
This means that I will have 28 = 256 IP Addresses availabile to me, with a range of 10.0.0.0 -> 10.0.0.255
Note: have to subtract off 5 IP Addresses, based on Amazon's documentation: "The first four IP addresses and the last IP address in each subnet CIDR block are not available for your use, and they cannot be assigned to a resource, such as an EC2 instance.
Source: https://docs.aws.amazon.com/vpc/latest/userguide/configure-subnets.html
Subnets:
In a Production App, I would create different Subnets for different Availability Zones. Each Subnet must reside in a single Availability Zone.
Since this is a learning project, I just used a single Subnet with a CIDR block that spanned the entire VPC.
Route Tables:
I created a new Route Table (leaving the default one alone) and explicitly assoicated it with my web-apps-subnet. This specifies how traffic should be routed, as the name would imply.
There are 2 routes. It is saying "any traffic within the range of 10.0.0.0/24 is considered local traffic within the VPC. All other traffic of 0.0.0.0/0 goes to the Internet Gateway igw-064640bbdb2f376ac
Security Group:
I have 2 inbound rules that allow for traffic on port 22 (so I can SSH into EC2 servers) and on port 8080 (port used by my Spring Boot App).
Network Interface (EC2):
My EC2 instance's Network Interface specifies the VPC, Subnet, and Security Group created in earlier steps.